The last half-decade has seen deep reinforcement learning (RL) agents learn to solve many exciting tasks, from beating humans in Go and Starcraft to solving Rubix cubes with a robotic hand. As real-world deployment of RL agents grows, there's an increasing need to understand the causal mechanisms of their behaviours
Causality provides a useful lense to understand the difficulty. In a standard feedforward network, the pattern of activations in one layer cause the particular pattern of activations in the next layer up, and so on through the network, from inputs to outputs. Because neural networks are fully differentiable, if we want to understand what inputs cause a neuron x to maximally light up in a feedforward network, we can backpropagate gradients of neuron x's activation (with respect to the inputs) through the layers to probe which inputs are most responsible for neuron x's activation. This tool is used in feature visualisation and attribution maps (cite featviz; building blocks). In a sense, backpropagation of gradients lets us trace causality back through the layers of the network.
- TODO: Footnote: Given that many modern deep RL agents use recurrent neural networks, it's worthwhile to note that these methods work in principle even for recurrent networks thanks to BPTT.
- TODO: Figure: an animated diagram of a csonv net activating one layer then activating the next.
- TODO: Another diagram that shows a visualisation of the maximally exciting image..
By contrast to standard neural networks, deep RL agents are situated in an environment. We can't use the same trick for RL agents because causality flows forward through both the agent's neural networks and its environment. For example: If an agent presses a lightswitch, causing a light to turn on, the agent's action caused its visual neurons to activate even though there are no 'action-neuron-to-visual-neuron' connections. The causality flowed through the environment, not through the agent's internal memory. When causality flows through the environment, we call this `external memory'.
- TODO: Footnote: ref to external memory and autostigmergy.
- TODO: An animated diagram of an MDP graph where each node is lighting up consecutively.
In most cases, the environment is not differentiable. This means we can't use gradient-based methods to ask what causes a neuron in a deep RL agent to have a particular activation at a particular timestep. To complicate matters further, we don't just want to study single neurons at single timesteps; what we actually want to understand in RL agents is the causal (neural) mechanisms of behaviour, where behaviour is a sequence of actions in a particular environmental context.
- TODO: Footnote: Justifying definition of behaviour. robot hand crushing human or grabbing pencil.
- TODO: A diagram illustrating a theoretical case of autostig where the MDP diagram only lights up the env nodes.
Previous work has skirted around these issues, typically by:
- Avoiding studying neural causal mechanisms entirely and focusing on external causes (cite Deletang);
- Focusing on studying the neural causal mechanisms of single actions at single timesteps (cite Rupprecht)
- Studying only the convolutional vision networks of feedforward (not recurrent) agents, without regard for understanding how behaviour is organised through time and without regard for the representations that link what the agent sees to how it acts.
In this article we address these issues. We first train a differentiable simulator of the environment in a recurrent neural network (cite Chiappa). This permits us to backpropagate gradients backwards through time, through both the environment and the agent (if the agent is recurrent). In turn, this permits the use of gradient-based causal attribution maps to generate explanations of the neural mechanisms of RL agents' behaviour. We believe that making gradient-based interpretability methods applicable to RL agents will be as important for understanding the neural activity of agents as they have been for understanding convolutional image classifiers. Our investigation motivates a shift of focus from a purely static feature-based interpretation of RL agent's networks toward a dynamics-based interpretation. To demonstrate the validity of the interpretations of the agent's neural activity that our method produced, we also manually modify the agents' neural dynamics and predict the changes in behaviour that were caused by our modifications.
Results
Simulating the environment in a recurrent network
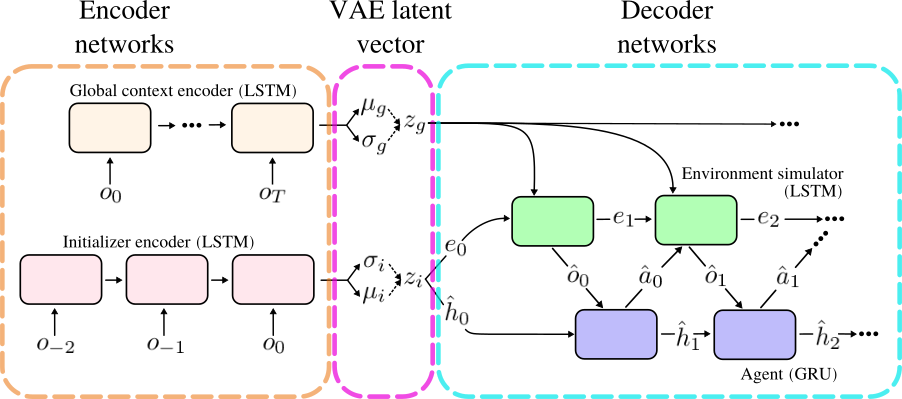
We developed a solution to agent interpretability that works in any environment (in practice, some environments may require too much computation). We trained a generative model to simulate the MDP, permitting us to study how agents use internal and external memory to organise behaviour. It's a VAE that simulates agent-environment rollouts... etc.
The agent is a component of the VAE decoder. But while the VAE is training, the agent's weights are fixed, so in the decoder only the environment dynamics are learned. The actions produced by the agent influence the how the environment unrolls. The environment dynamics are independent of the specific agent used in the decoder, demonstrated in figXXX where we use a trained vs untrained agent. In the third panel the agent isnt even implemented by a neural network - it is hardcoded only to chooses "jump right". In all cases, the environment dynamics remain roughly realistic. This is important for preserving external memory in cases where the agent uses it to control its behaviour. While there are similarities, our approach stands in contrast to recent model-based RL approaches train a environment model so that the agent can use it in order to represent latent environmental variables (cite Ha and Schmidhuber 2018) or to plan (cite Buesing et al. 2018; Hafner et al. 2018/2020, other refs). Instead, the environment model we train is separate from the agent and is not how the agent represents the world or selects its actions. It is a stand-in for the external environment that the agent was trained in; less a 'mental model of the world', more 'The Matrix'.
Optimising generated samples to maximise/minimise certain neurons' activity
This builds on previous work that use generative visualisation to understand RL agents (cite Rupprecht). But previous work only generated single image frames, not image sequences, and therefore could not be used to interpret how behaviour is coordinated through time.
Since the generative model is fully differentiable, we can optimise the VAE latent space vector used by the generator generates the samples so that they have certain interesting properties, such as cases where the agent experiences large drops in value (unexpected failures) or cases where the agent takes specific sequences of actions (like consistently moving backwards).
We can even optimize the activity of hidden state neurons such that they are maximally or minimally activated, a method as is commonly used to interpret vision networks. But when we do this, we find that most neurons in the agent's hidden state are difficult to interpret. It's not clear what they encode. This hints at important differences between the interpretation of RL agents and convolutional networks.
When representations associated with RL (task representations) have been studied in neuroscience, they have exhibited strong 'mixed-selectivity' - they appear to be selective for multiple task features (cite papers from review). Features in the input tend to activate groups of neurons, also called directions in neural statespace. Dimensionality reduction techniques can help identify those directions in neural statespace. PCA, the dimensionality reduction method that we use here, can intuitively be thought of as identifying the groups of neurons that most commonly fire together. Stated more accurately, PCA identifies the directions in neural statespace that explain most of the variance of their firing.
When we generate agent-environment rollouts that maximally activate agent's hidden state neurons in the directions of the ICs, we find that the visualisations look more meaningful. Here we find directions that appear to correspond to XYZ.
Using saliency to dissect the causal mechanisms of behaviour
So far, the evidence that indicates that certain directions in neural statespace represent certain task features has been correlative. We want to be able to tell if the features we've identified actually cause the activity to move in that direction in neural statespace. In neuroscience, showing causation is usually difficult and requires interventional experiments. But in our generative model, it is easy; we can use attribution/saliency maps. Saliency maps identify how much each input or neuron causes downstream neuron to fire. We can therefore explore causality in our simulated system by analysing the gradients of certain neurons with respect to others.
For example, we can measure how much each directions in the agent's neural statespace contributes to a particular action by measuring the alignment of the saliency vector with that statespace direction. Blue colours mean those directions (groups of neurons) positively contributed to that action, and red colours indicate negative contributions.
We've just shown how directions in the agent's neural state space causally respond to observations of specific features in the environment. But the hidden state does more than respond to what the agent sees - it also determines behaviour. We can identify how much an action a certain timestep is caused by observations of components of the agent's neural statespace (figxxx). These samples depict an agent that jumps over a buzzsaw in the 20th timestep. The saliency plots depict the contribution of the observation and the directions in the agent's neural statespace to that action. We can see by the saliency map that the buzzsaw contributes to the jumping action just before the jump. The buzzsaw-selective direction in neural statespace also contributes to the jumping action.
Behaviours are more than single actions - they are a sequence of actions in a particular environmental context. In our generative model, behaviours can be described by sequences of vectors: the activities of the environment simulator network and action logits in sequential timesteps. We can therefore describe behaviours by a canonical set of vectors averaged over many instances of such behaviours. If we measure the contribution of observation pixels and agent hidden state directions to the alignment of the environment activity vectors and action vectors with the vectors that are canonical of that behaviour, we can determine how much they 'caused' that behaviour.
Consider the behaviour "jumping onto a chasm island" (TODO story text here and describe figure)
Validating our interpretations by modifying the agent's neural dynamics
Our understanding of a neural network is only as good as the predictions it enables us to make about it. We therefore tried to predictably control the agent's behaviour. To do this, we 'swap' certain directions in the agent's neural statespace: for example, at any timestep where the agent's networks cause its hidden state to move in the direction of the buzzsaw-representation, we instead move it in the direction of the box-representation.
It is safe for the agent to land on boxes, but the agent dies if it lands on buzzsaws. In samples where the buzzsaw direction is swapped for the box direction, we see that the agent jumps onto buzzsaws much more often.
TODO: Statistics. Maybe a bar chart to depict. % of samples with deaths by buzzsaw. % of episodes of where the agent jumps on a box. Both stats with and without swap of buzzsaw direction and box direction.Similarly, when we replace the chasm-with-island direction with the chasm direction, the agent dies by jumping into chasms much more often, as would be expected if the agent thought it were going to land safely on an island.
TODO: Statistics. Maybe a bar chart to depict. % samples where the agent dies by falling into chasms. % samples where agent lands on an chasm island. Both stats with and without swap of buzzsaw direction and box direction.Discussion
Using a generative environment simulation, we have begun to understand the neural dynamics that govern the behaviour of a simple deep RL agent. Importantly, we have been able to identify the causal components of these dynamics and use our understanding to predict the results of modifications to the agent.
In line with previous work (cite Activation atlases, that French author, anything in the review on point), we found that combining several interpretability methods together has yielded much deeper understanding than any individual method alone. Chiming with other work (cite activation atlases, Hilton, etc), we have found two combinations to be particularly useful: 1) combining dimensionality reduction methods with saliency maps and 2) combining saliency maps with generative feature visualization. We believe that finding other useful combinations of interpretability methods is an exciting avenue of future research.
At least for RL agents, our investigation motivates a shift of focus from a purely-feature based interpretation of a neural network toward dynamics-based interpretation of RL agents' networks. We also highlight the necessity of studying both internal and external memory for understanding the causal mechanisms of agent behaviour. We believe these emphases will be important to ensure that our interpretations of RL agents do not contain blind-spots.
Our method has limitations:
Learning an environment simulator can be a challenge: It may be hard to simulate all environments well enough for this method to work. Indeed, we made the simulator's job easier by turning off the background images so that the backgrounds were only black. Even then, samples from our simulator exhibit some imperfections such as resumption after reaching the coin. And games with richer environmental dynamics, such as CaveFlyer, looked out of reach of a model of our size, though we did not train a CaveFlyer-environment simulator to completion. However, our environment simulator (an LSTM with 1024 units with a shallow unsampling convolutional decoder) is relatively small and architecturally primitive; it is very likely possible to train better environment simulators using more modern architectures.
Deterministic dynamics: The simulations generated here explore only deterministic sequences of modal actions. They therefore do not explore behaviour that may be non-modal, which may therefore exclude a potentially large proportion of important behaviours.
Other agents: The method we propose here works for agents that are fully differentiable (since we pass gradients through the stochastic sampling of actions). It might not be as straightforward to adapt the method to agents with non-differentiable components, such as those that use symbolic components.
Despite these limitations, the approach opens up many exciting new possibilities for deep RL agent interpretation:
Layer-by-layer analysis: Here we focused our analyses only on the agent's hidden state. This is only one layer of the agent. Generative visualisation has been used to build up a layer-wise understanding of convolutional image classifier networks and the same is possible here. Understanding all of the layers of the agent (and to some extent the environment simulator) is necessary to understand how the agent transforms its various inputs within and across timesteps to compute its behaviour.
Safe training and un-training of the agent: While training our generative model, we kept the weights of the agent fixed and trained only the weights of the environment simulator. But it is also possible to fix the weights of the environment simulator and retrain the agent. If we can identify undesirable behaviours exhibited by the agent in simulation (for example by optimizing for generating samples where the agent assigns high value to states humans deem bad), we may be able to retrain the agent by generating examples of that behaviour and penalizing the agent from within the safety of the simulation.
Scaling to more complex agents and tasks: The agent and task-environment studied here, although non-trivial, are nevertheless simple compared with what is possible. Larger agents trained on more interesting and complicated tasks may yield more interesting task representations. Although we mentioned scaling as a potential limitation, there is nevertheless hope for scaling our method to highly capable future agents. One source of hope is the representational capacity of large networks seems capable of learning surprisingly rich representations of the world. Another potential source of hope is that future agents may well be model-based and therefore learn their own model of the environment. We may be able to leverage their internal world model to supplement the external environment simulator; we may therefore need only to train an external environment simulator to learn the inaccuracies in the agents' world model and learn to represent those environmental variables that the agent is using as external memory. The method may thus scale with the capability of the agent.
Artificial neuroethology: The behaviours we analyzed here were chosen by hand, but it would be better to systematically identify behaviours using unsupervised learning so that we can comprehensively study their neural mechanisms. This endeavour has a name: artificial neuroethology (cite Beer, Cliff, Merel etc). The method proposed here has all the necessary ingredients to do so: representations of environmental variables, actions, and agent neural activity. And, perhaps for the first time, we also have a straightforward way to identify the environmental variables that are causally relevant for agent behaviour -- saliency maps over dimensions of the environment representation.
A tool for neuroscience: Computational neuroscientists often study the solutions learned by artificial neural networks in order to generate hypotheses about the solutions to tasks learned by animals. But studying the causal structure of the solutions learned by artificial RL agents has been a challenge due to the non-differentiability of the environment. Our method offers a way to study the solutions to naturalistic (deterministic) tasks that artificial agents learn, which will serve as a useful tool for neuroscientific hypothesis generation.
Training agents in natively differentiable environments: Given the potential difficulty of training environment simulations for more complex environments, we may be better to work with agents that are trained in environments that are designed to be differentiable (cite), since our approach suggests that environment differentiability is useful for agent interpretation.
End of article
Just retaining the below hints because they'll probably be useful as a reference.
Hot reloading
Your browser can automatically refresh when your editor saves. This should work by default, and you can disable it in index.js. Sometimes hot reloading isn't fully compatible with all types of code, so you may need to try manually reloading if you're seeing inconsistent behavior.
Formulas
Here's a test of an inline equation$ signs:
Citations
We can